基於語義音訊的講者專屬配音與翻譯整合解決方案(COMP7705 MSc(CompSc) 最終年專案)
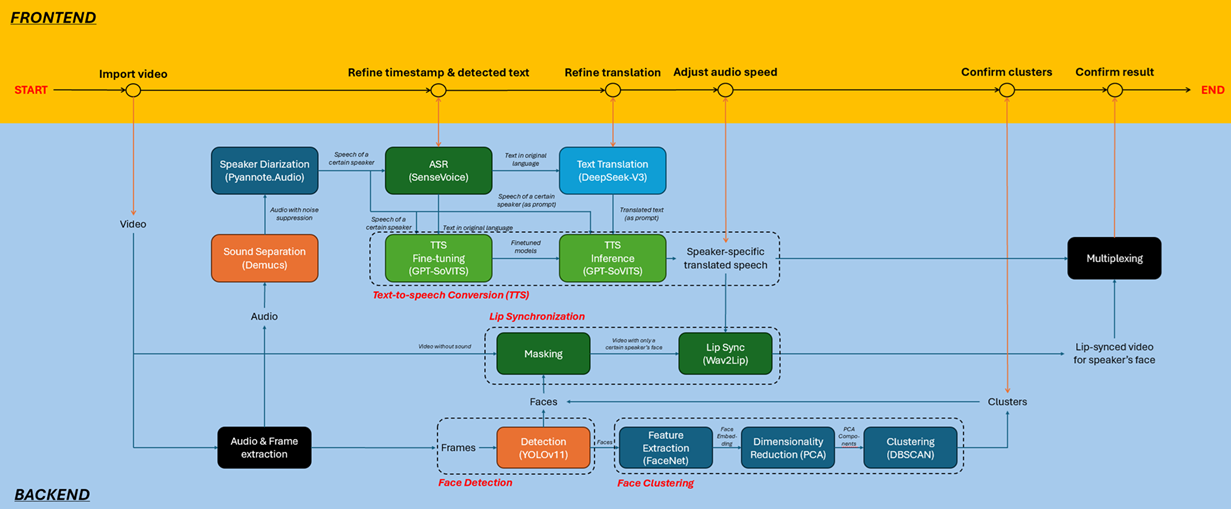
本項目提出了一個整合的 AI 解決方案,具備一個基於網頁的用戶入口,用於講者專屬的配音和翻譯。該系統處理輸入的原始語言(例如英語)視頻並生成翻譯輸出(例如廣東話),同時保留原講者的聲音特徵,包括語音和語調。項目關鍵在於通過唇部同步技術(lip sync)保持真實感,使翻譯語音與講者的唇部動作對應,從而提供更好的視覺體驗。此外,該解決方案支持多講者視頻,通過講者區分、臉部檢測和臉部聚類技術來準確識別和處理各個講者的語音和面孔。
系統目的是開發一個先進的 AI 驅動視頻本地化管道,集成最新技術,實現高質量、講者感知的翻譯和配音。通過結合講者區分、自動語音識別(ASR)、神經語音克隆、機器翻譯、講者專屬文本轉語音(TTS)、臉部檢測/聚類及 AI 驅動唇部同步技術,系統旨在:
1. 在翻譯中保留講者身份
準確將英語翻譯為廣東話,同時保留原講者的語音特徵,包括語調、情感和音高,使用神經語音克隆(GPT-SoVITS)。這確保翻譯語音自然流暢,並保持講者的獨特語音,避免傳統 TTS 系統產生機械化或單一的語音,從而提升配音質量和沉浸感。
2. 優化英語至廣東話的翻譯,具備未來擴展性
重點解決語言上複雜的英語到廣東話翻譯任務,針對音調變化和口語表達等挑戰進行調整。該管道的模組化設計使其能夠輕鬆擴展至其他語言(例如普通話、日語),只需最小的架構變更,保證廣泛適用性。
3. 實現真實的唇部同步
利用唇部同步技術(通過 Wav2Lip)生成精確的唇部動作,使其與翻譯後的廣東話語音相匹配,考慮語音的音素細節和語音節奏。即使是快速或富有表現力的對話,系統也能確保視覺一致性,增強觀眾的沉浸感。
4. 無縫處理多講者視頻
透過強大的區分技術(Pyannote.Audio)和臉部聚類技術(FaceNet & DBSCAN),準確將語音歸屬於正確的講者,處理多講者的視頻,確保群體對話、訪談或動態場景中的語音與唇部匹配。
影響與創新
本解決方案通過自動化傳統的勞動密集型本地化流程,在製作流程和媒體無障礙性上實現了顛覆性的改進。該技術通過減少對人類配音員和人工編輯的依賴,顯著降低了成本和周轉時間,預計能將廣東話內容的配音成本降低約 40-60%,同時保持高品質的工作成果。除經濟效益外,它還使小型內容創作者和教育機構能夠更容易地進行高品質本地化,打破了傳統配音服務的高門檻。這一系統突破了目前的自動字幕和普通配音工具的限制,保留了原講者的語音特徵並捕捉語言的細微差別(例如語調變化、成語表達),達到了文化和交流上的真實性,促進了全球知識交流的公平性,並為 AI 驅動的媒體本地化設立了新的標杆。