Integrated Solution for Speaker-specific Dubbing and Translation with Semantic Audio (COMP7705 MSc(CompSc) Final Year Project)
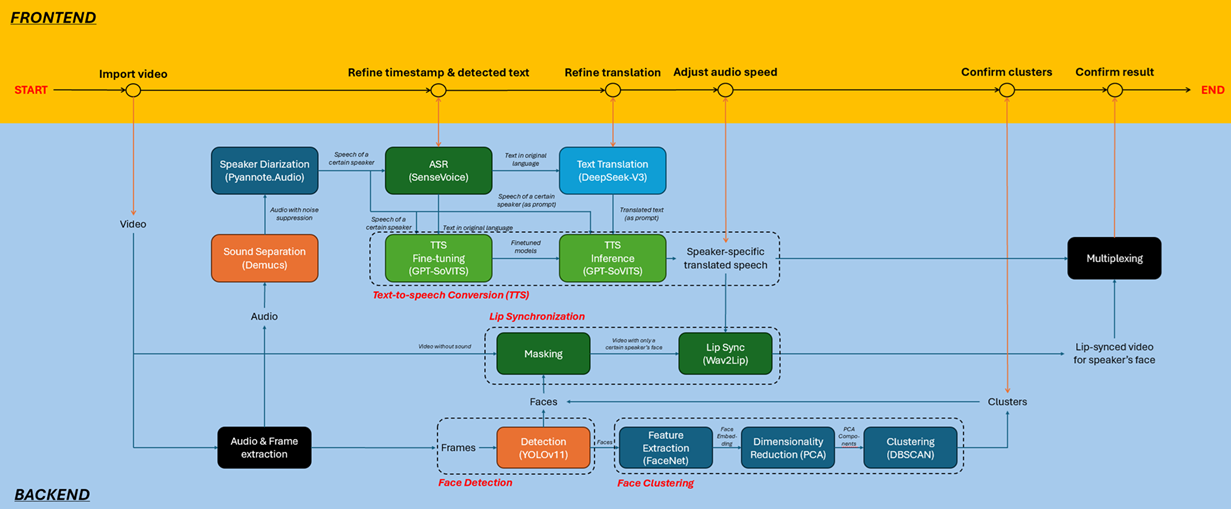
This project proposes an integrated AI-powered solution featuring a web-based user portal for speakerspecific dubbing and translation. The system processes input videos in a source language (e.g., English) and generates translated output (e.g., Cantonese) while preserving the original speakers' vocal characteristics, including voice and tone. A key focus is maintaining realism through lip synchronization (lip sync), aligning translated speech with the speakers' lip movements to enjoy a better visual experience. Additionally, the solution supports multi-speaker videos by leveraging speaker diarization, face detection, and face clustering to isolate and process individual voices and faces accurately.
To develop an advanced AI-powered video localization pipeline that integrates cuttingedge technologies to achieve high-quality, speaker-aware translation and dubbing. By combining speaker diarization, automatic speech recognition (ASR), neural voice cloning, machine translation, speaker-specific text-to-speech (TTS), face detection/clustering, and AI-driven lip-sync, the system is designed to:
1. Preserve Speaker Identity in Translation
Accurately translate spoken English to Cantonese while retaining the original speaker’s vocal characteristics, including tone, emotion, and pitch, using neural voice cloning (GPT-SoVITS). This ensures the translated speech sounds natural and maintains the speaker’s unique voice, avoiding the robotic or generic output of traditional TTS systems and enhancing dubbing quality and immersiveness.
2. Optimize for English-to-Cantonese with Future Scalability
Focus on the linguistically complex English-to-Cantonese translation task, addressing challenges such as tone sandhi and colloquial expressions. The pipeline’s modular design allows for future adaptation to other languages (e.g., Mandarin, Japanese) with minimal architectural changes, ensuring broad applicability.
3. Achieve Realistic Lip Synchronization
Generate precise lip movements with lip synchronization technology (via Wav2Lip) that matches the translated Cantonese speech, accounting for phonetic nuances and speech rhythm. The system ensures visual coherence, even for rapid or expressive dialogue, enhancing viewer immersion.
4. Handle Multi-Speaker Videos Seamlessly
Process videos with multiple speakers through robust diarization (Pyannote.Audio) and face clustering (FaceNet & DBSCAN), accurately attributing speech to the correct individual. This enables consistent voice-lip pairing in group conversations, interviews, or dynamic scenes.
Impact & Innovation
By automating traditional labor-intensive localization processes, this solution delivers transformative improvements across production workflows and media accessibility. The technology significantly reduces costs and turnaround times by minimizing reliance on human voice actors and manual editing, cutting dubbing expenses by an estimated 40-60% for Cantonese content while maintaining studioquality output. Beyond economic efficiency, it democratizes access to high-quality localization for minority languages like Cantonese, empowering smaller content creators and educational initiatives that previously faced prohibitive barriers to professional dubbing services. Crucially, the system advances beyond current auto-captioning and generic dubbing tools by preserving the original speaker's vocal identity and capturing nuanced linguistic features (e.g., tone sandhi, idiomatic expressions), achieving authenticity that bridges both cultural and communicative gaps. These innovations collectively foster more equitable global knowledge exchange while setting new benchmarks for AIassisted media localization.